

データレイクの基本定義と概要

データレイクは、さまざまな形式のデータをそのまま蓄積するデータ基盤です。ここでは、データレイクの定義や特徴などを見ていきましょう。
データレイクとは?
データレイクとは、元の形式をそのまま保存できるデータストアです。例えば、売上表や在庫台帳などの構造化データ(行と列で構成されたデータ)、センサーログやウェブアクセスログなどの半構造化データ、画像や動画、音声などの非構造化データなど、加工前のデータを集約する場所です。
IPA(情報処理推進機構)では、データレイクを以下のように定義しています。
データレイクとは、多様なデータソースからデータの加工や変換をせずに、元の形式のままデータを保存するデータストアである。(引用元:IPA 「DX白書2023 第5部 DX実現に向けたITシステム開発手法と技術」)
データレイクは保存前にスキーマを定義せず、生データの状態で蓄積できる仕組みを持ち、分析や活用の目的に応じて後から整形できます。そのため、データウェアハウスだけでは難しかった多種多様なデータを扱え、柔軟にデータを蓄積することが可能です。
データレイクと最新技術の親和性
多様な形式の生データを蓄積できるデータレイクは、最新技術との高い親和性があります。AIや機械学習、IoTやビッグデータ解析との相性が良いデータ基盤です。
例えば、製造業ではIoTセンサーから取得した稼働データや異常検知用の音声データを蓄積し、予知保全モデルの学習に利用できます。小売業であれば、POSデータやECサイトの行動履歴、在庫情報などを一元管理し、需要予測やレコメンド精度の向上に役立てることが可能です。
さらに近年では、データレイクとデータウェアハウスの長所を統合した「レイクハウス」という新しい仕組みも登場しています。従来のデータレイクは「自由だけど整理されていない」、DWHは「整理されているけど柔軟性が低い」という弱点がありました。レイクハウスはその両方を解決し、データを柔軟に保存しながらも、整然と管理・分析できる仕組みです。
データレイクとデータウェアハウス・データマートの違い

データ活用の基盤には、データレイクのほかにもデータウェアハウス(DWH)やデータマートといった仕組みがあります。それぞれの特徴と役割を理解することが重要です。
データレイク
データレイクは「スキーマオンリード」方式を採用し、保存時点では構造を固定せずにデータを保存できます。構造化・半構造化・非構造化データを一元的に保管できるため、将来の未知の分析やAIモデルの学習などにも対応可能です。
ただし、生データをそのまま保存するため、活用時には整形やクレンジングなどの前処理が必要です。
データウェアハウス(DWH)
データウェアハウスは格納前にデータ構造を定義・整形する「スキーマオンライト」方式を採用しています。そのため、格納時点で分析に最適化された状態になっており、複雑な結合や大量集計も高速で処理が可能です。
例えば、販売実績や在庫状況を日次で集計し、経営会議用の定型レポートを生成する業務では、データウェアハウスが最も効率的です。
ただし、データレイクの保存容量が無制限であるのに対し、データウェアハウスは保存前に決めたスキーマに基づいて保存するため、容量が制限される点には注意しなければなりません。
データマート
データマートは、特定の部門やプロジェクトが必要とするデータのみを切り出して形成した小規模なデータベースです。例えば、営業部門なら顧客情報や取引履歴のデータ、製造部門なら設備稼働や品質管理のデータなど、利用目的に合わせたデータ構造を持ちます。そのため、部門単位で導入・運用でき、かつ各部門の担当者が直接管理できるため、日常業務に密着した分析が可能です。
以下、表にそれぞれの特徴を簡単にまとめました。
| 項目 | データレイク | データウェアハウス | データマート |
|---|---|---|---|
| データ構造 | スキーマオンリード(生データのまま保存) | スキーマオンライト(格納前に整形・最適化) | 部門用途に合わせた構造 |
| 対応データ形式 | 構造化・半構造化・非構造化すべて対応 | 主に構造化データ | 主に構造化データ |
| 保存容量 | 無制限(ペタバイト級も可能) | 選別格納(分析に必要なデータを最適化して保存) | 限定的(部門単位の必要範囲) |
| 活用までの時間 | 長い(利用時に前処理が必要) | 短い(整備済みデータを即利用) | 短い(対象範囲が限定される) |
| 用途 | 探索分析、AI学習、将来の活用に備えた長期保管 | 定型レポート、KPIモニタリング、経営層向け集計 | 部門ごとの特定業務分析 |
データレイクのメリット

データレイクは、さまざまなデータ形式を柔軟に扱える点が大きな魅力です。ここでは、データ蓄積容量や多様なデータ形式、拡張性における主な3つのメリットを見ていきましょう。
低コストで大容量データ蓄積
データレイクはクラウドストレージを活用することで、ペタバイト級のデータを保存することが可能です。また、オンプレミス環境では、大量のストレージ増設やハードウェア更新に高額な投資が必要ですが、クラウドでは使用容量に応じた従量課金が一般的なため、初期費用を抑えられます。
例えば、製造業では、設備稼働ログを数年間保存して時系列で傾向を分析するケースが増えているため、クラウドストレージのデータレイク利用が適しています。
データを低コストで長期間保持できることは、データ活用やAI導入などを実践する企業にとって大きなメリットです。
多様なデータ形式の保存と高度な分析活用
データレイクは、構造化データだけではなく、画像や動画、音声やセンサーデータなどの非構造化データをそのまま保存可能です。そのため、従来は別々のシステムに保管されていたこれらデータを一元管理できます。つまり、多様なデータを横断的に分析できるようになるということです。
例えば、製造現場ならば、画像検査データとセンサーの稼働ログを組み合わせて、品質不良の原因の特定に活用できます。また、小売業では、カメラ映像と購買履歴を連携することで、店舗内の動線分析や陳列改善に活用できるでしょう。
このように、単一でのデータだけでは実現できない分析が可能になることが、大きなメリットの一つです。
クラウド基盤によるスケーラビリティ
クラウド上に構築されたデータレイクは、必要に応じてストレージや処理能力を迅速に増減できます。オンプレミスでは増設に数週間から数カ月かかることもありますが、クラウドならば短時間でリソースの追加が可能です。データ量が増大する繁忙期だけスケーリングするなどの柔軟な対応も可能です。
また、企業の成長や環境変化に合わせて調整できるデータレイクは、多拠点展開や海外進出を進めるなどのシーンでも大きなメリットになります。
データレイク導入時の課題とリスク

データレイクは大量かつ多様なデータを扱える柔軟な基盤です。
しかし、導入すればすぐに成果が出るわけではありません。「毎日エクセルで集計に追われている」、「既存のBIではデータ量が多すぎて処理が重い」という現場も少なくありません。こうした状況のままデータレイクを導入すると、十分に活用できない可能性があります。
ここでは、データレイク導入時に陥りやすい課題やリスクを見ていきましょう。
データスワンプ化の危険性
データスワンプ化とは、データが整理されていないために、データの所在や意味が分からない状態になることです。データ形式や内容の異なるデータを保存できるデータレイクでは、無秩序に取り込まれたデータが把握できなくなると、分析や検索に多大な時間がかかるケースが発生します。
例えば、スキーマやメタデータが付与されていないデータが蓄積されると、後から活用する際に追加の調査や変換が必要となり、そのコストが膨らんでしまいます。さらに、用途不明のデータが増えると保存領域が無駄に消費され、結果としてストレージコストや管理負荷が高まってしまうのです。
ガバナンスとセキュリティの欠如
データレイクのガバナンスとセキュリティの欠如は重大なリスクとなります。
ガバナンス面では、データの定義や命名規則、メタデータ管理が統一されていないと、利用時に同じ指標でも部門ごとに意味が異なるなどケースが出てきます。また、だれがどのデータを作成・更新したのかといったログを残さない運用は、データや分析結果の品質や信頼性を担保できません。
セキュリティ面では、アクセス権限や認証ルールの運用が重要です。セキュリティへの意識が低い状態では、機密情報や個人情報が意図せず共有されるリスクが高まります。適切な権限設定、通信や保存データの暗号化、利用履歴を残す監査ログが不可欠です。
“宝の持ち腐れ”状態の懸念
データレイクに情報を収集しても、利用可能な形式に変換・加工しなければデータ活用はできません。蓄積後は、データを活用するためのフォーマット統一などの前処理を、効率的に進められる環境を整備する必要があります。
意思決定に必要な分析結果がタイムリーに提供できない状態は、機会損失を招くだけではなくデータ活用そのものの信頼性を損ないかねません。そして「データレイクは役に立たない」といった誤った印象が社内に広まり、宝の持ち腐れとなってしまいます。
データレイクを活かすために必要な仕組み

データレイクを「データを蓄積するだけの場所」にしてしまっては、その価値を発揮できません。ここでは、データを業務で活用するために欠かせない仕組みについて見ていきましょう。
データ基盤の整備と統合
データレイクに集めたデータは、そのままでは分析や業務活用には向きません。構造化データや半構造化データ、非構造化データのいずれであっても、メタデータの付与やフォーマット変換などの前処理が不可欠です。
また、これまで部門ごとに独立して管理されてきたデータを統合し、全社で共有できるデータ形式にすることも大切です。
データレイクを導入する際には、初期段階から仕組みの整備と統合プロセスを明確に設計し、運用ルールを定めておきましょう。これにより、データレイクはデータが溜まるだけの資産ではなく、意思決定を支える基盤になります。
データウェアハウス・データマートとの連携
データレイクは多様な情報をありのまま蓄積できます。ただし、分析やレポートにすぐ使える形ではありません。企業の意思決定に必要な数値や指標を提示するためには、データウェアハウスやデータマートとの連携が不可欠です。
データ活用の流れとしては、データレイクに集めた生データをデータウェアハウスに移し、統一された構造や定義に沿ってデータクレンジングします。さらに、部門ごとに最適化したデータマートを設けて、営業や製造、経営企画などそれぞれの現場が必要とする切り口でデータを保管し、BIツールなどで可視化するといったイメージです。
データレイクは素材置き場としての役割を担い、データウェアハウスやデータマートがその素材を意思決定に使える形へと変換するのです。
Dr.Sum(ドクターサム)が実現する「使えるデータ基盤」
Dr.Sumは、データを集めて整え、必要な形にして利用できる状態で蓄積する「データ分析基盤」を構築するためのソリューションです。散在する情報を統合し、分析や可視化にすぐ使える状態に整えます。
これにより、部門や利用者ごとの加工負荷を減らし、組織全体のデータ活用を可能にします。ここでは、データ基盤としての仕組みや特徴を見ていきましょう。
Dr.Sum Connect(ドクターサムコネクト)による生データ整理・統合
企業内には、ERPや販売管理、CSVやエクセルファイルなど、さまざまな形式や粒度のデータが存在します。これらを一括で取り込み、必要な項目を抽出・変換して統合できるのが、Dr.Sum のデータ連携ツールに当たる「Dr.Sum Connect」です。
データ粒度の不一致や表記ゆれなどを事前に解消し、全社共通で利用できる「ひとつの正しいデータソース」を形成します。
Dr.Sumを活用することで、例えば、各部門が行っていた複雑なエクセル加工や手作業の集計が不要となり、分析や戦略立案に集中できるようになります。
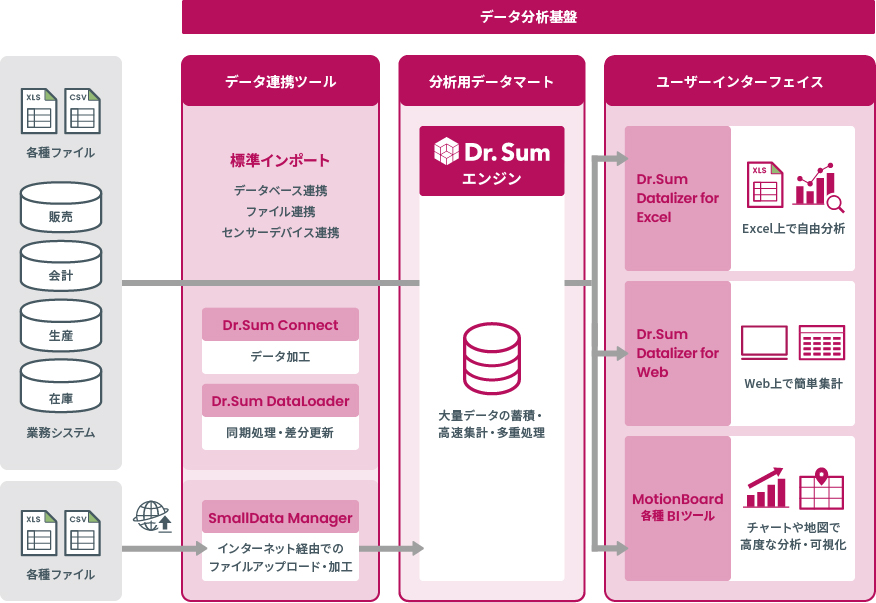
大規模データも高速処理:現場から経営層まで自在に活用可能
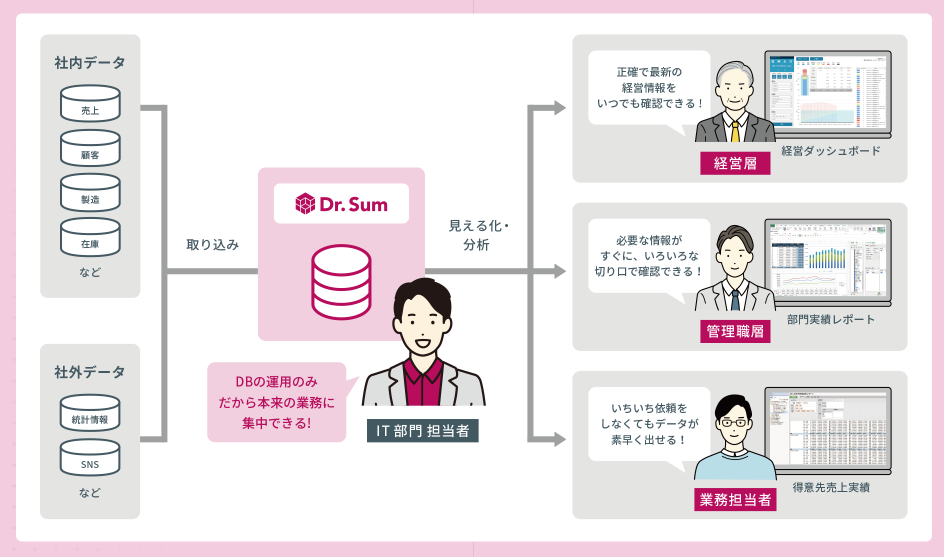
Dr.Sumの「Dr.Sum エンジン」は、大容量データでも条件変更や深掘り分析を短時間で実行できます。従来のように、IT部門の担当者にデータ抽出依頼をして結果を待つ必要はありません。
利用者(経営層や管理職層)が自ら条件を指定して、即時に集計結果を取得できます。これにより、分析サイクルが短縮され、タイムリーな意思決定を可能にします。
BIツール「MotionBoard(モーションボード)」との連携強化でデータ活用の最大化
Dr.Sumは、MotionBoardなどのBIツールと連携して蓄積データをリアルタイムに可視化できます。ダッシュボード上で全体状況を把握し、必要に応じてドリルダウン分析に切り替えながら、問題の原因を迅速に特定していくなどのデータ活用が可能です。
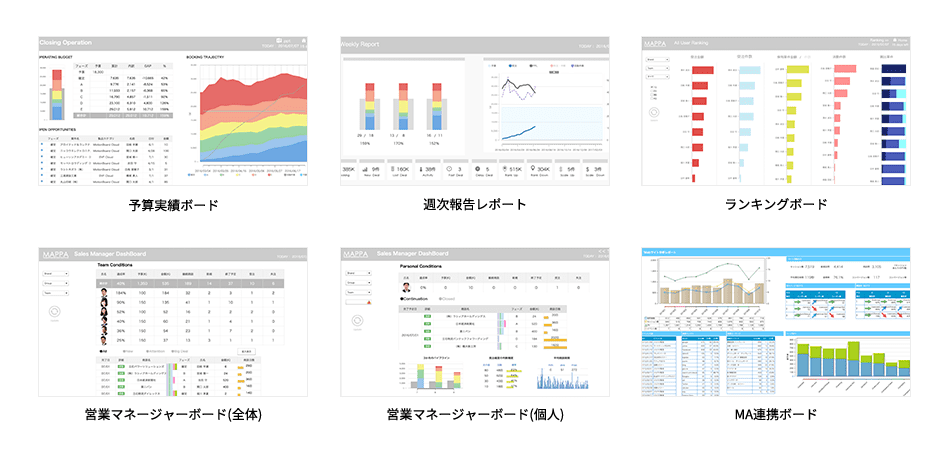
また、可視化した画面を複数人で共有することで、認識のずれをなくし、会議やレポート作成の効率も大幅に向上させます。
まとめ
データレイクはデータ構造を問わず、多様なデータをそのまま蓄積できる柔軟なデータストアです。しかし、導入しただけでは十分な価値を発揮できません。必要なのは、データの整備や統合、その他データ基盤との連携です。
特に、エクセルや既存BIでは処理しきれない大容量・多様形式のデータを扱う場合には、データレイクとデータウェアハウス、データマートを組み合わせて、自社にあった運用を設計することが大切です。
これから、データレイクやデータウェアハウスなどでデータ活用を検討している企業は、ぜひデータ活用基盤のDr.Sumをご検討ください。






